http://graphics.cs.cmu.edu/projects/deepContext/
Unsupervised Visual Representation Learning
by Context Prediction
Presented at ICCV 2015
People
Abstract
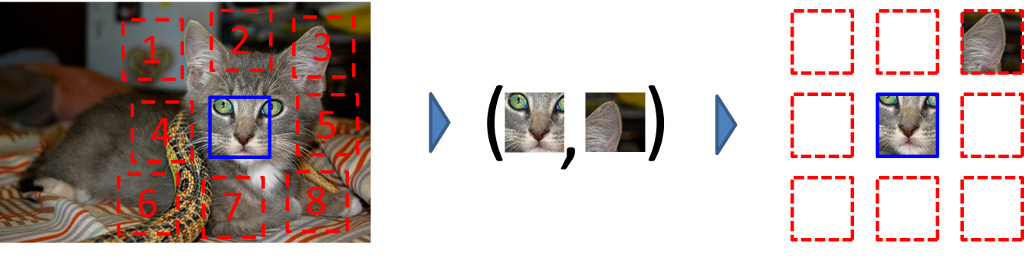
This work explores the use of spatial context as a source of free and plentiful supervisory signal for training a rich visual representation. Given only a large, unlabeled image collection, we extract random pairs of patches from each image and train a convolutional neural net to predict the position of the second patch relative to the first. We argue that doing well on this task requires the model to learn to recognize objects and their parts. We demonstrate that the feature representation learned using this within-image context indeed captures visual similarity across images. For example, this representation allows us to perform unsupervised visual discovery of objects like cats, people, and even birds from the Pascal VOC 2011 detection dataset. Furthermore, we show that the learned ConvNet can be used in the R-CNN framework and provides a significant boost over a randomly-initialized ConvNet, resulting in state-of-the-art performance among algorithms which use only Pascal-provided training set annotations.
Video
Paper & Presentation
|
|
Citation |


Code and Network
|
Code | ||||||||
is available on Github | ||||||||
|
Pre-trained Network | ||||||||
|
These trained networks can be used to extract fc6 features from 96-by-96 patches. Note that running it requires a version of Caffe later than August 26, 2015, or the normalization will be computed incorrectly. Images should be passed in in RGB format after the per-color-channel means have been subtracted, but no other preprocessing is necessary (the pixel range is automatically scaled correctly). For instructions on using them to extract features for larger images, see the net surgery example in the Caffe repository. python3 magic_init.py -cs -d '/path/to/VOC2007/JPEGImages/*.jpg' \ --gpu 0 --load /path/to/inputmodel.caffemodel \ /path/to/groupless_caffenet.prototxt /path/to/outputmodel.caffemodel where groupless_caffenet refers to this modified version of the default CaffeNet model that has groups removed (for the vgg-style model, this becomes this vgg-style prototxt). You can then do the fine-tuning with fast-rcnn with the caffenet model using this prototxt for training, this solver, and this prototxt for testing. You can use this, this, and this, respectively, for VGG. For magic_init, start with the .caffemodel's that don't have fc6. Also, make sure you use fast rcnn's multiscale configuration (in experiments/cfgs/multiscale.yml). If you're using VGG, this configuration will most likely run out of memory, so use this configuration instead. Run 150K iterations of finetuning for the caffenet model, and 500K for VGG. |
|
Projection Network: |
[definition prototxt] [caffemodel_with_fc6] [caffemodel_no_fc6] |
|
Color Dropping Network: |
[definition prototxt] [caffemodel_with_fc6] [caffemodel_no_fc6] |
|
VGG-Style Network (Color Dropping): |
[definition prototxt] [caffemodel_with_fc6] [caffemodel_no_fc6] |
Additional Materials
|
Full Results: Visual Data Mining on unlabeled PASCAL VOC 2011 | ||||||||
|
This is the expanded version of Figure 7 in the paper. We have two versions, depending on the method used to avoid chromatic aberration at training time. WARNING: These pages contain about
10000 patches; don't click the link unless your browser can handle it! | ||||||||
|
Nearest Neighbors on PASCAL VOC 2007 | ||||||||
|
This is the expanded version of Figure 4 in the paper. We have a separate page for each feature, corresponding to
the three columns in Figure 4.
In each case, the leftmost column shows randomly selected patches that were used as queries; no hand-filtering was done. | ||||||||
|
Maximal Activations of Network Units | ||||||||
|
We report here the patches that maximally activated the units in our networks. For each unit, we show a 3-by-3 grid of the top 9 patches. The units themselves are arranged in no particular order. We ran the networks on about 2.5M randomly-sampled patches from ImageNet. Note that most units have a receptive field that does not span the receptive field; hence, we only show the approximate region that is contained within the receptive field. Regions outside the patch are shown as black.
| ||||||||
|
Deep Dream | ||||||||
|
Alexander Mordvintsev decided to visualize the contents of our VGG-style network by applying Deep Dream separately to each filter in our network, and has kindly shared his results with us. Below are 8 of the filters in conv5_3 (the second-to-last layer before the representations are fused). Below each is my interpretation. Mouse over them to see it (I don't want to bias your interpretation!)
|







Related Papers
We first proposed context as supervision in:
C. Doersch, A. Gupta, and A. A. Efros. Context as Supervisory Signal:
Discovering Objects with Predictable Context European Conference on Computer Vision, September 2014.
A paper that helps us fine-tune our model:
P. Krähenbühl, C. Doersch, J. Donahue, and T. Darrell. Data-dependent Initializations of Convolutional Neural Networks International Conference on Learning Representations, May 2015.
An extension of this paper, which trains deep nets with jigsaw puzzles:
M. Noroozi and P. Favaro. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles arXiv:1603.09246, March 2016.
|
Other works on “Self-Supervised” Learning |
|
P. Isola, D. Zoran, D. Krishnan and E. Adelson Learning visual groups from co-occurrences in space and time arXiv:1511.06811, November 2015
P. Agrawal, J. Carreira and J. Malik Learning to See by Moving ICCV 2015
D. Jayaraman and K. Grauman Learning image representations tied to ego-motion ICCV 2015
X. Wang and A. Gupta Unsupervised Learning of Visual Representations using Videos ICCV 2015
|
Funding
This research partially was supported by:
- Google Graduate Fellowship to Carl Doersch
- ONR MURI N000141010934
- Intel research grant
- NVidia hardware grant
- Amazon Web Services grant
Comments, questions to Carl Doersch