Dynamic Units of Visual Speech
| Sarah Taylor | Moshe Mahler | Barry-John Theobald | Iain Matthews |
Proceedings of the 2012 ACM SIGGRAPH/Eurographics Symposium on Computer Animation (2012)
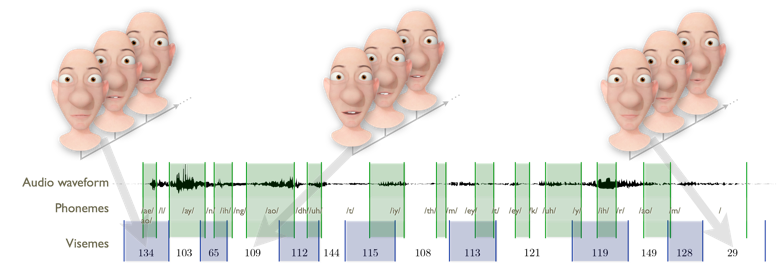
We present a new method for generating a dynamic, concatenative, unit of visual speech that can generate realistic visual speech animation. We redefine visemes as temporal units that describe distinctive speech movements of the visual speech articulators. Traditionally visemes have been surmized as the set of static mouth shapes representing clusters of contrastive phonemes (e.g. /p, b, m/, and /f, v/). In this work, the motion of the visual speech articulators are used to generate discrete, dynamic visual speech gestures. These gestures are clustered, providing a finite set of movements that describe visual speech, the visemes. Dynamic visemes are applied to speech animation by simply concatenating viseme units. We compare to static visemes using subjective evaluation. We find that dynamic visemes are able to produce more accurate and visually pleasing speech animation given phonetically annotated audio, reducing the amount of time that an animator needs to spend manually refining the animation.
Sarah Taylor, Moshe Mahler, Barry-John Theobald, Iain Matthews (2012). Dynamic Units of Visual Speech. Proceedings of the 2012 ACM SIGGRAPH/Eurographics Symposium on Computer Animation.
@inproceedings{Taylor2012:Dynamic,
Author = {Sarah Taylor and Moshe Mahler and Barry-John Theobald and Iain Matthews},
booktitle = {Proceedings of the 2012 ACM SIGGRAPH/Eurographics Symposium on Computer Animation},
Title = {Dynamic Units of Visual Speech},
year = {2012},
location = {Lausanne, Switzerland},
numpages = {10},
publisher = {ACM},
}
